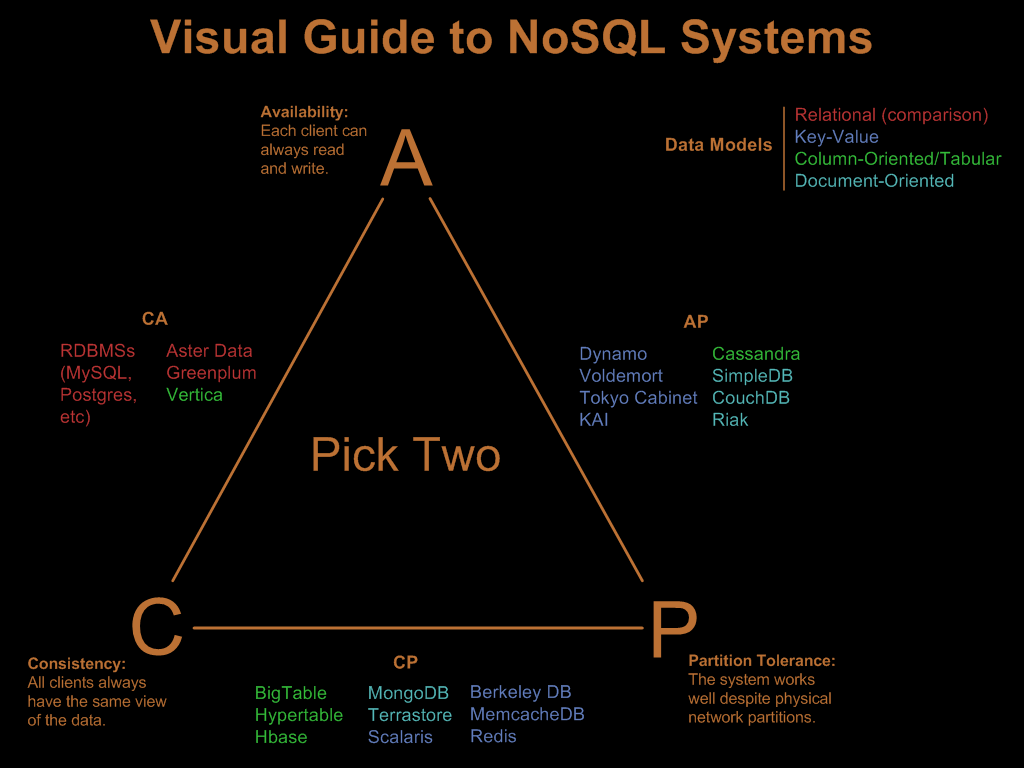
Teorema de Brewer o CAP
A la hora de utilizar una base de datos en un sistema distribuido el Teorema de Brewer o CAP ofrece una guía para elegir la mejor solución que se adapte al caso de uso que queremos solucionar. En la actualidad, con el desarrollo de sistemas en la nube es importante conocer este teorema a la hora de diseñar una aplicación y elegir el tipo de base de datos más adecuado.
El teorema viene a decir que un sistema distribuido solo puede ofrecer dos de las tres características que idealmente un sistema de este tipo debe ofrecer:
-
Consistencia (C). Todos los clientes ven los mismos datos al mismo tiempo, independientemente del nodo al que se conecten. Para conseguirlo, siempre que se escriban datos en un nodo, éstos deben reenviarse o replicarse al instante a todos los demás nodos del sistema antes de que la escritura quede confirmada. De esta forma, una lectura siempre devolverá la escritura mas reciente.
-
Disponibilidad (A). Siempre que se realiza una solicitud de datos se debe obtener una respuesta válida en un periodo de tiempo razonable, incluso si hay nodos inactivos.
-
Tolerancia de partición (P). El sistema debe permanecer estable y continuar trabajando a pesar de las interrupciones de comunicación que se produzcan entre los nodos que lo componen.
Puesto que solo dos de estas características pueden garantizarse a la vez, por tanto, tenemos tres posibles tipos de base de datos:
-
Base de datos CP. Se garantiza la consistencia de los datos entre los diferentes nodos y se permiten las interrupciones entre los nodos pero a costa de la disponibilidad de los datos, pues el sistema puede fallar o tardar en ofrecer una respuesta a una petición realizada.
-
Base de datos AP. Ofrece disponibilidad y tolerancia de partición a costa de la consistencia. Cuando se produce una interrupción entre nodos todos permanecen disponibles, pero entre aquellos que han sufrido la interrupción habrá algunos que tendrán una versión de los datos más antigua ya que no todos los nodos estarán sincronizados.
-
Base de datos CA. Se garantiza la consistencia de los datos y la disponibilidad de los mismos. Para conseguirlo se deben evitar las interrupciones entre nodos, por lo que no se puede ofrecer tolerancia a errores.
En el último caso, hay que tener en cuenta que en el mundo real las interrupciones entre lo nodos de un sistema distribuido no se pueden evitar, por lo que en la práctica la implementación de este tipo de base de datos tiene que afrontar este inconveniente. Las bases de datos relacionales de toda la vida son CA ya que tradicionalmente se han implementado de forma que las escrituras y lecturas se hacen sobre la misma copia de los datos. A partir de aquí, cada producto a desarrollado sus propios mecanismos de replicación para poder trabajar en una arquitectura distribuida con diferentes nodos.